
01
通过xpath查找元素,将状态为完成的订单批量发货。
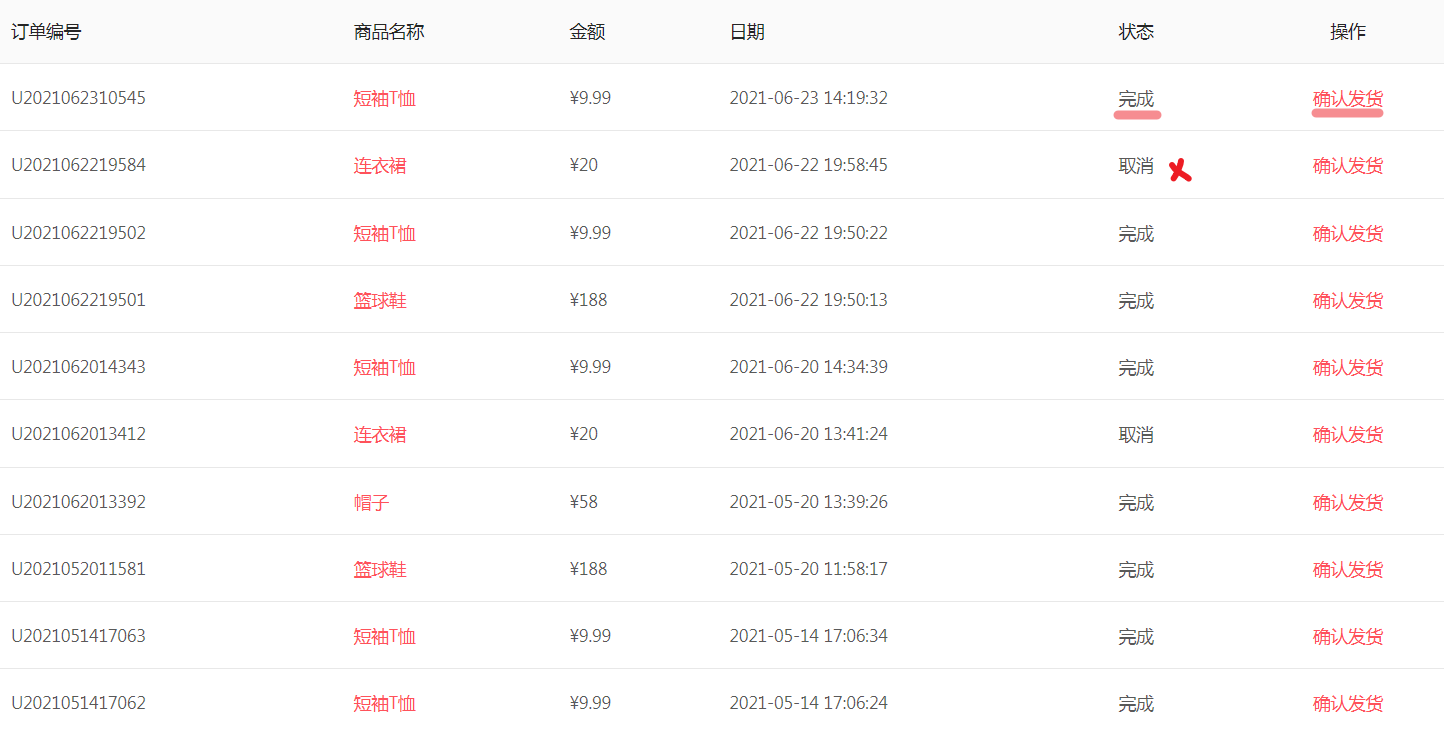
1、「获取相似元素列表」:通过元素值=完成,找到状态的td,再用 .. 找到父级元素一条订单。//*[text()="完成"]/..
2、循环找到的相似元素列表。
3、「获取元素对象」:通过关联之前的父元素订单和地,找到循环到的当前“确认发货”a标签,并点击。.//a[text()="确认发货"] (ps. 关系父元素时作用xpath要在最前面加上 . 表示当前元素)
4、「获取元素对象」找到再次确认按钮并点击。
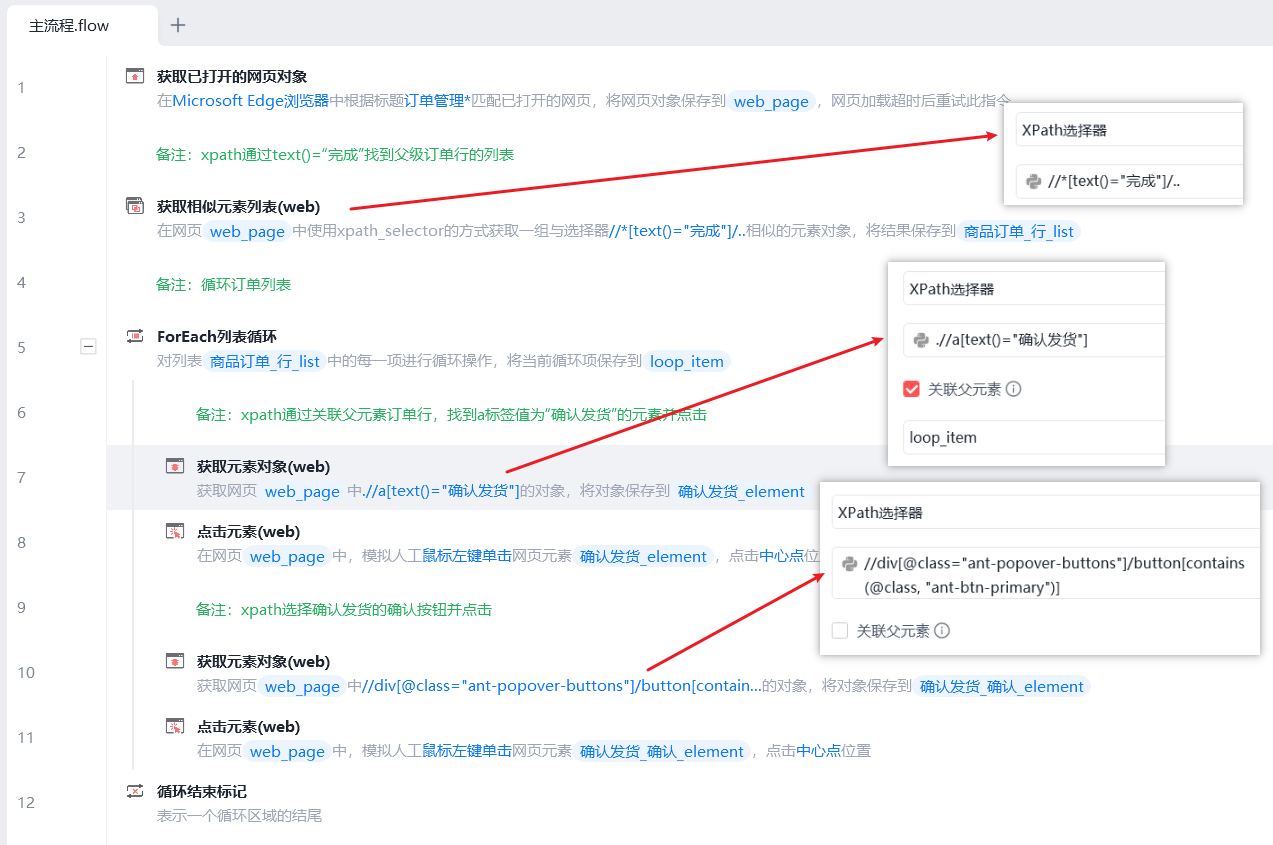
02
通过查找输入框前的文本为“价格”,再在输入框中输入“¥100.00”。

1、使用xpath查找属性值等于“价格”,再用 following-sibling 查找当前节点结束标签之后的同级节点下的input,也就是输入框。 //td[text()="价格"]/following-sibling::td/input
2、在输入框中填写内容。
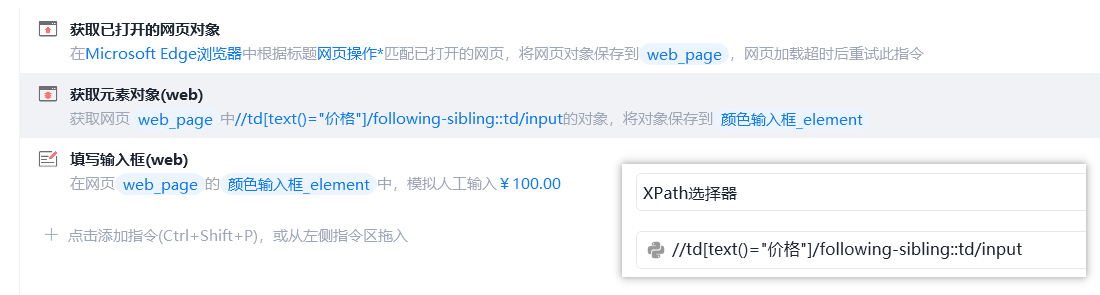
03
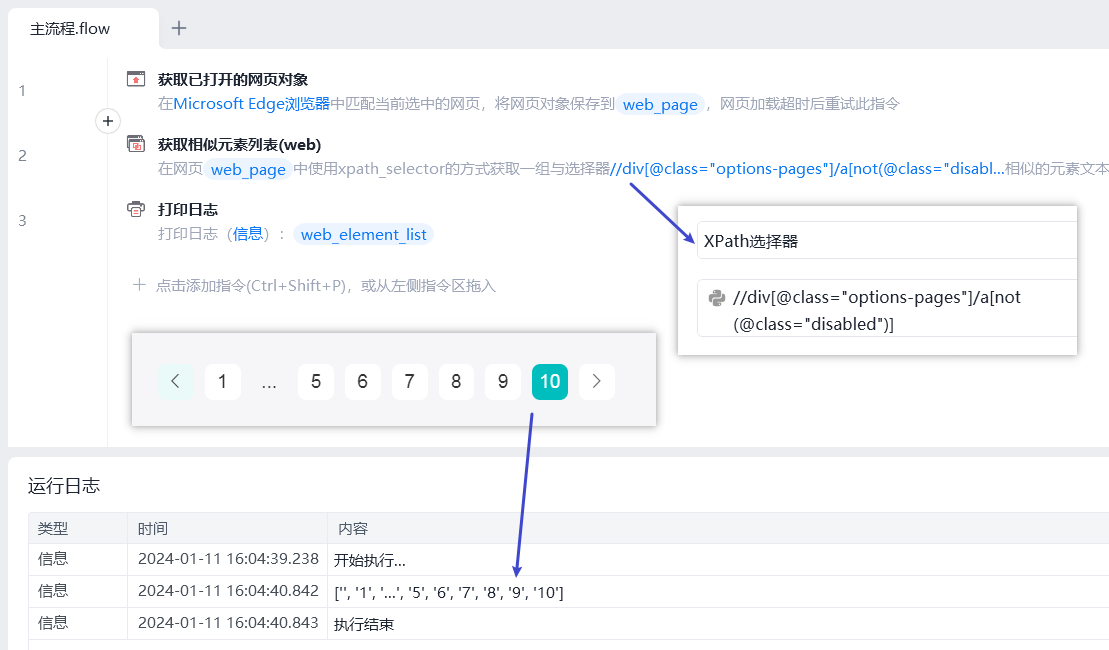
捕获所有相似元素组,除了下一页不可点击的按钮。
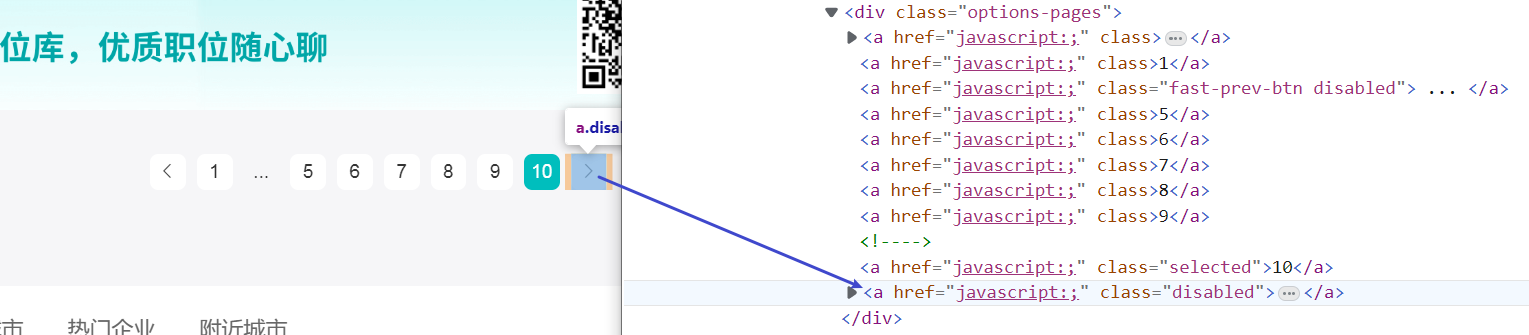
作用 not 进行排除属性值为disabled的元素。 //div[@class="options-pages"]/a[not(@class="disabled")]
04
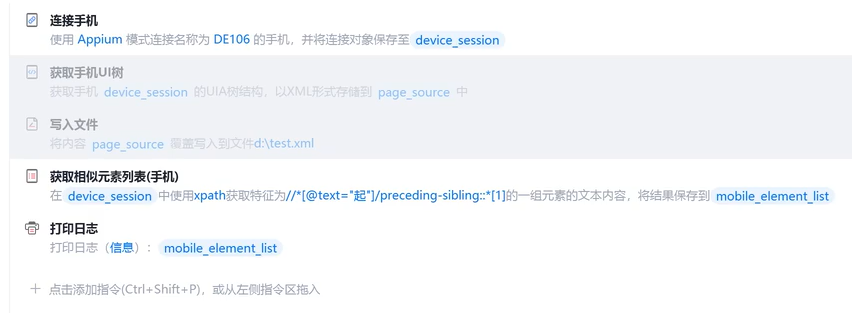
通过“起”字查找价格元素。
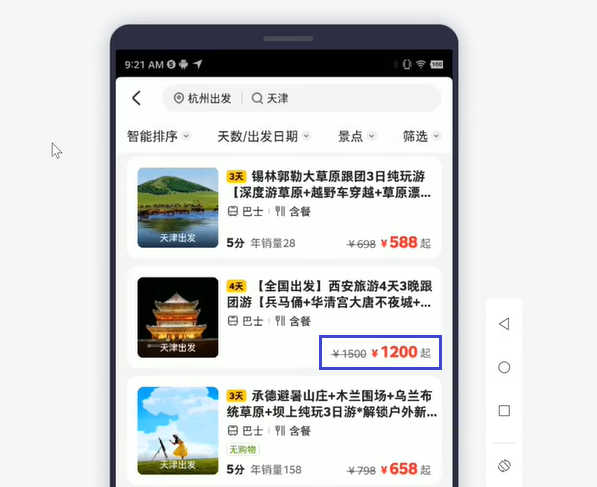

//*[@text()="起"]/preceding-sibling::*[1]
ps. 使用prceding-sibling获取到的同级节点,是按文档顺序的反向进行排序的,它的前一个就是1而不是last()。
去除弹窗
去除弹窗的2条通用 xpath 命令:

XPath跨域
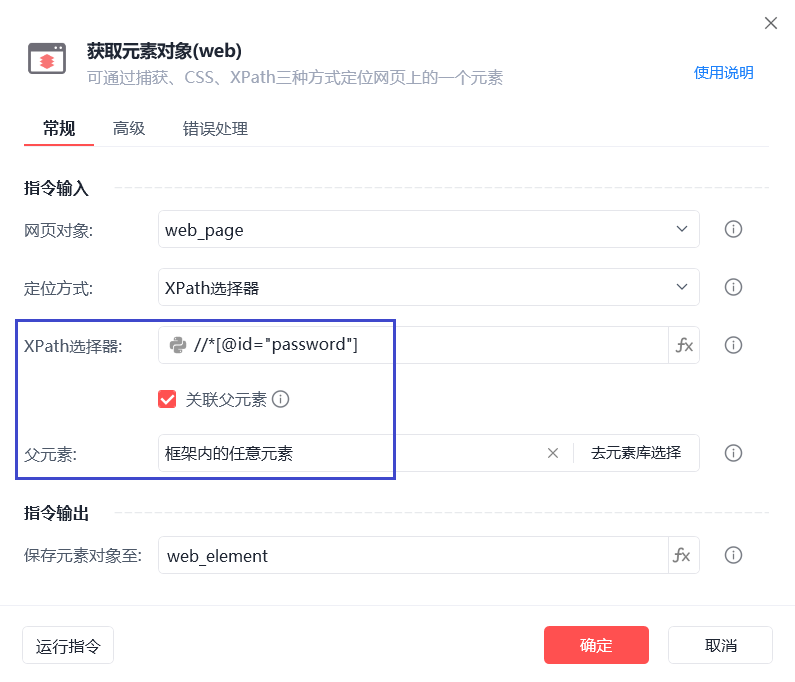
网页中内嵌网页时(淘宝生意参谋登陆页面),xpath无法捕获,需要联系父元素跨域捕获。
SVG元素
普通方式无法获取SVG元素。
//*[name()="svg"]获取所有name等于svg的标签//div[@class="icon"//*[name()="svg"]]再通过div进行定位(如果页面有多个svg)
XPath和影刀
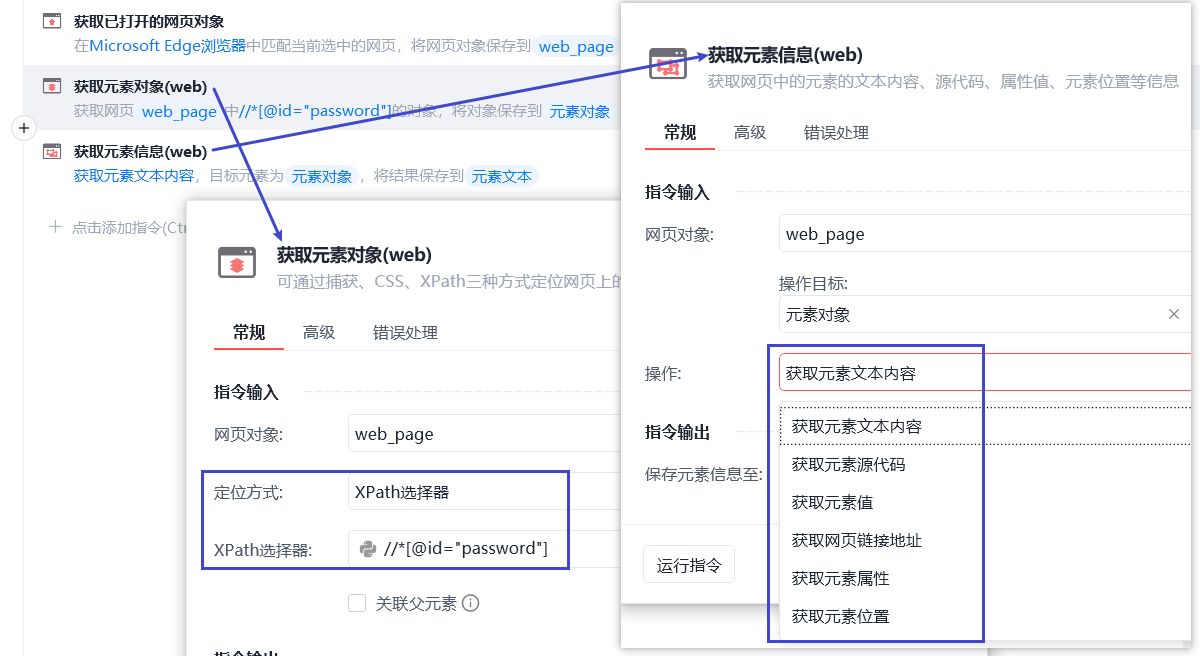
xpath可以直接提取文本属性和值,比如 //div/a[2]/text() 取出标题文字。
但影刀中这样操作就会报错。
因为影刀的指令「获取元素对象」获取的是元素对象,查询结果必须是一个元素,不能是文本或者属性值。
应该先通过「获取元素对象」获取元素,再使用「获取元素信息」提取文本或属性值。
微信扫一扫,分享到朋友圈
 in <b>/www/wwwroot/rpa.eryoude.com/wp-content/themes/8.5.8/includes/share/share.php</b> on line <b>89</b><br />
NC_BASE_URLmodules/qrcode/qrcode.php?data=https%3A%2F%2Frpa.eryoude.com%2F80.html)
