

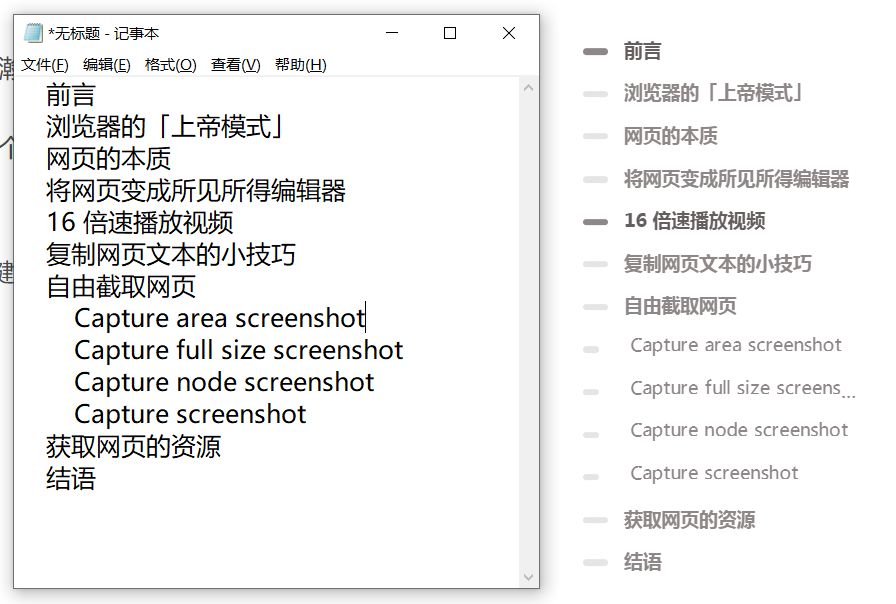
有些文章干货很多,但网站并不提供目录(TOC “Table of Contents”),阅读体验并不好。
那我们能不能使用 RPA 快速抓取文章标题目录,并在记事本中显示出来?
如下图,左侧记事本是使用 影刀RPA 抓取的,右侧是网站自带的目录 TOC 。
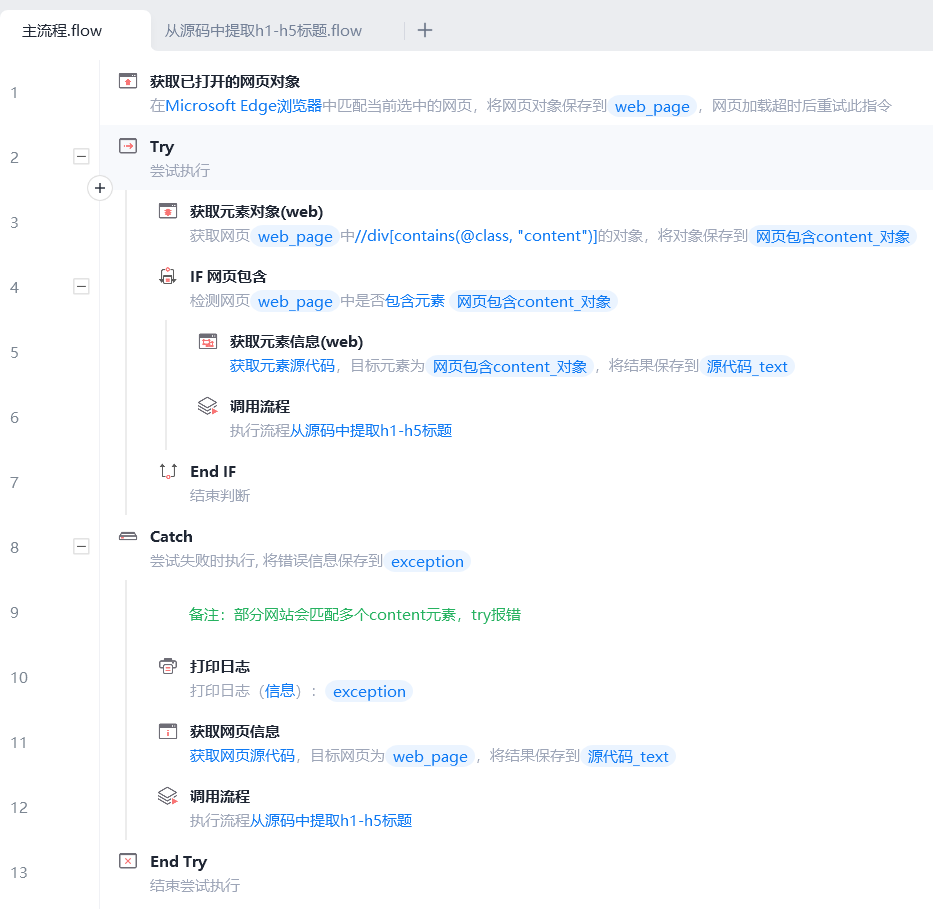
RPA 流程
第一步,获取网站源码
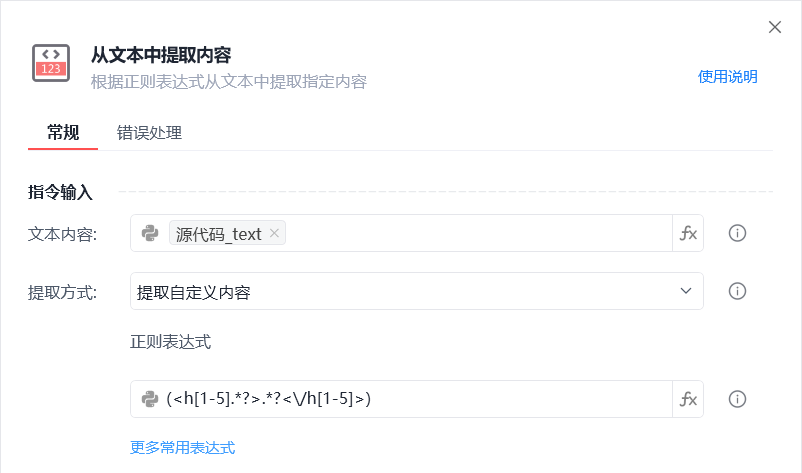
我们可以直接从网站源码中抓取所有的 h1 到 h5 标签,也就是文章标题。但这时也会包含不需要的网站侧边栏标题这些。
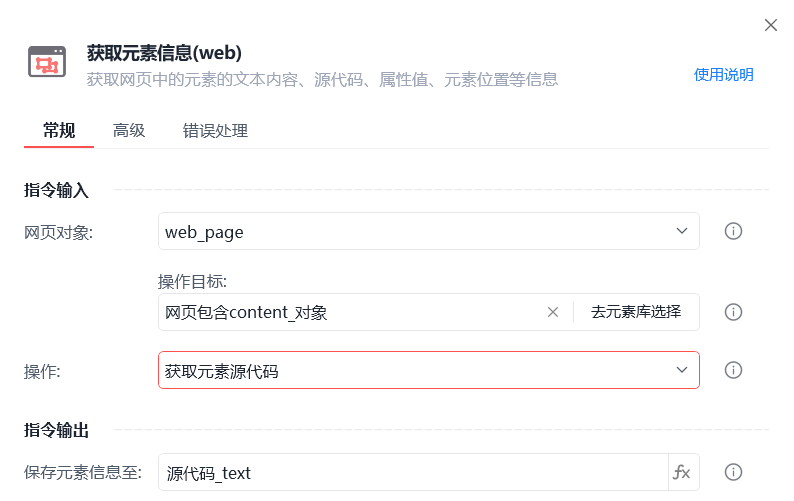
如果是针对某个特定的网站就容易解决了,直接获取网站正文的元素对象,再获取元素对象的源代码。
不过这样子通用性就不好了,只适用于特定网站。
通过 F12 查看网站源码,发现很多网站的正文都是放在 <div class="content">文章正文</div> 这样一个标签内的。
div的属性值一般是 content 或者 post-content 这种。
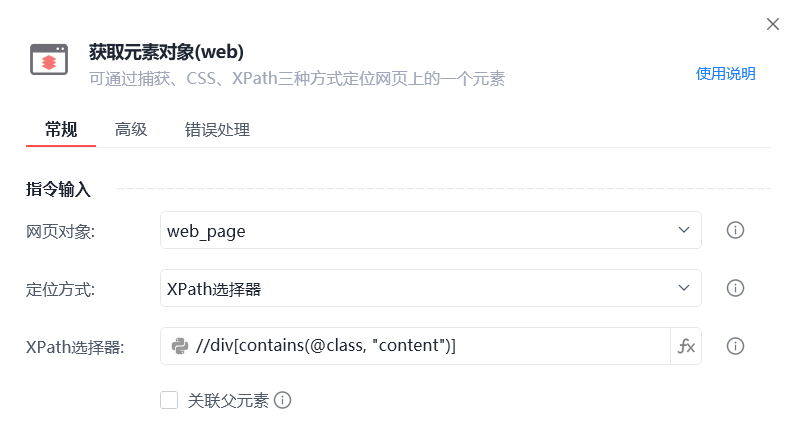
那我们就先通过 XPath 选择器查找网页正文的元素对象,再在元素对象中获取正文的源码。
当网页中没有这个元素对象时,再使用整个网站的源码提取。
有多的,总比没有的好。
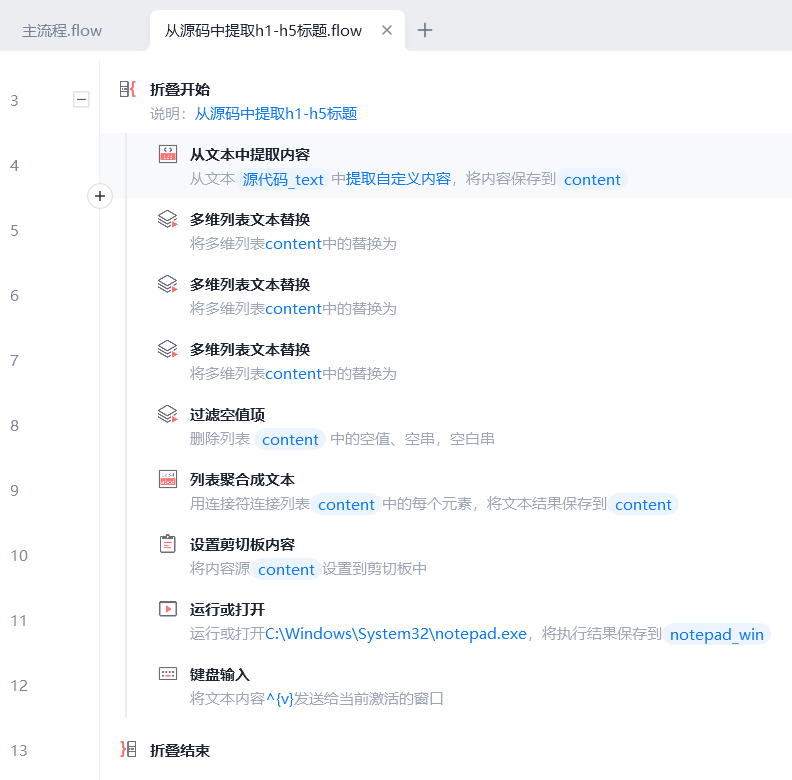
第二步,获取h1-h5标签
通过源代码获取所有的h1到h5标签,组成列表。
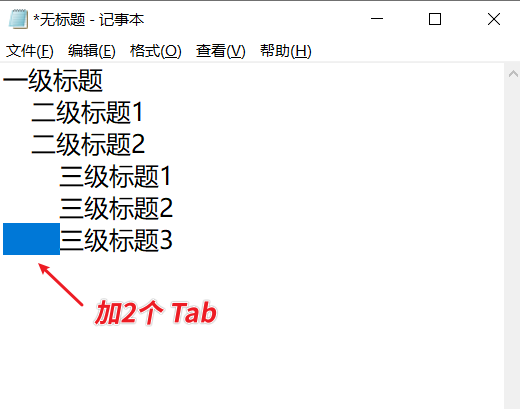
二级标题前加1个tab,三级标题前加2个tab,让标题显示更直观。
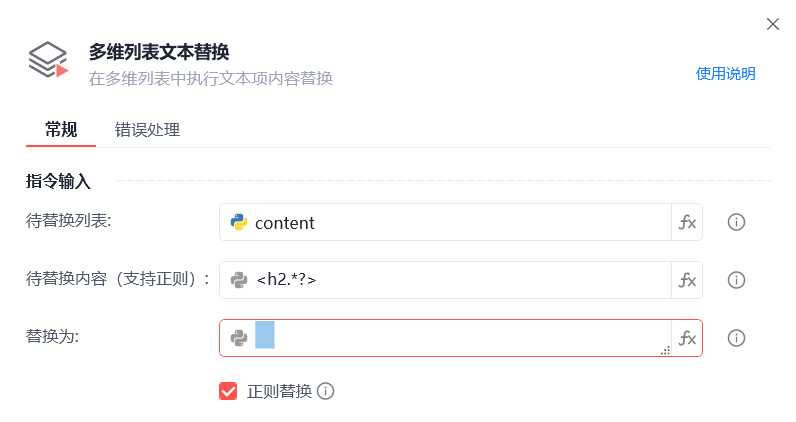
使用「多维列表文本替换」指令删除并必要的 span a 等等标签。
使用「过滤空值项」指令删除空值。
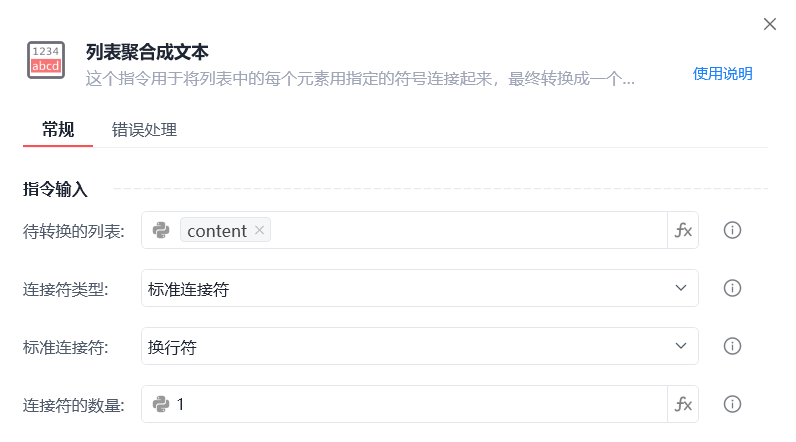
使用「列表聚合成文本」指令,将列表用换行符组合成文本。
第三步,复制到记事本
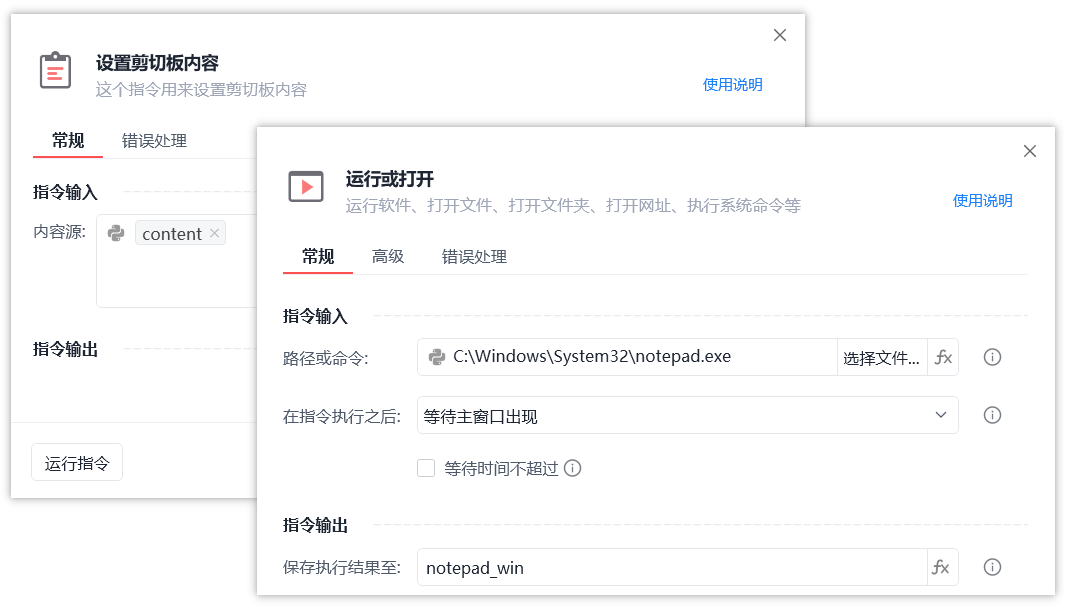
将处理好的目录文本复制到剪贴板。
打开一个记事本txt文件,ctrl+v 粘贴目录。
完成。
RPA 源码
使用方法
1、打开要生成目录的网页;
2、运行影刀RPA(通过快捷键触发或者手动点击运行按钮);
不足
因为不是为某个网站单独定制,只是通用的匹配了一下,生成的目录结尾可能会有多余的内容(比如网站侧边栏的标题)。
如果只是针对某一个特定网站就容易了,直接获取文章正文的元素对象,再从源码中提取目录。
微信扫一扫,分享到朋友圈
 in <b>/www/wwwroot/rpa.eryoude.com/wp-content/themes/8.5.8/includes/share/share.php</b> on line <b>89</b><br />
NC_BASE_URLmodules/qrcode/qrcode.php?data=https%3A%2F%2Frpa.eryoude.com%2F98.html)
